10th Annual State of the Software Supply Chain®



Figure 4.1 Average Number of Packages Per Application
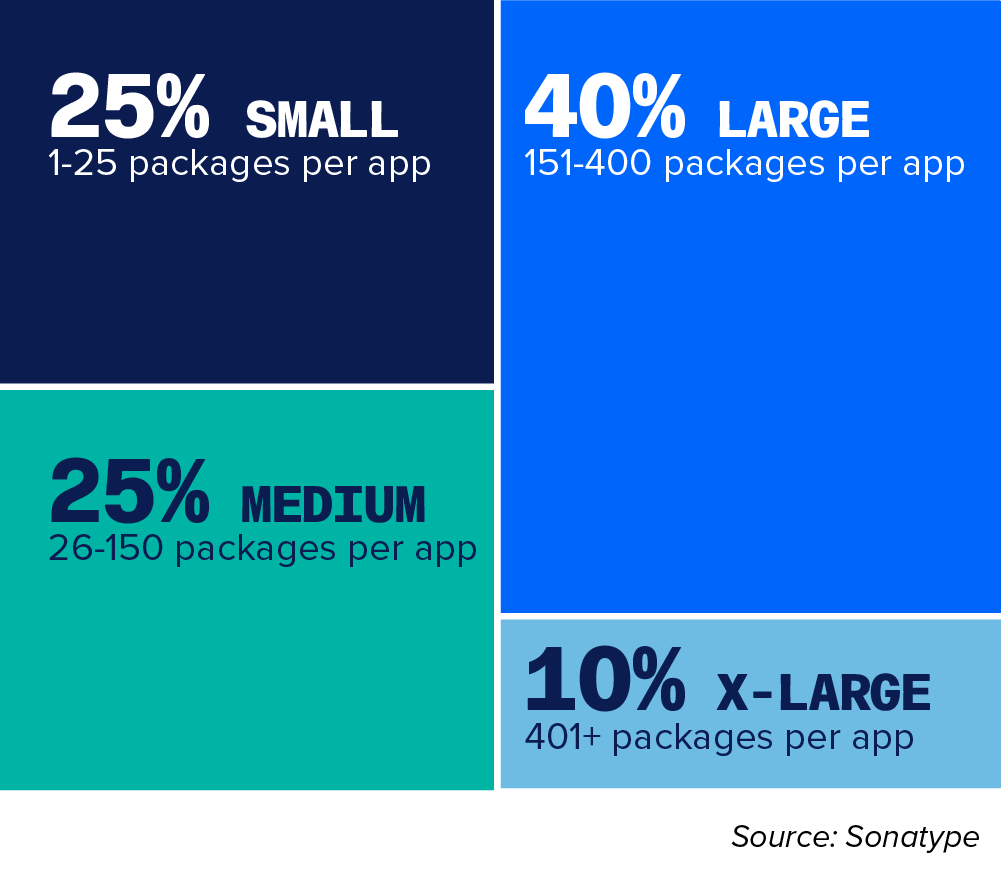
This chart shows the distribution of application dependency size. Small: up to 25 dependencies; Medium: 26 to 150 dependencies; Large: 151 to 400 dependencies; X-Large: 401 or more dependencies.
Figure 4.3 Score Corrected Aggregations
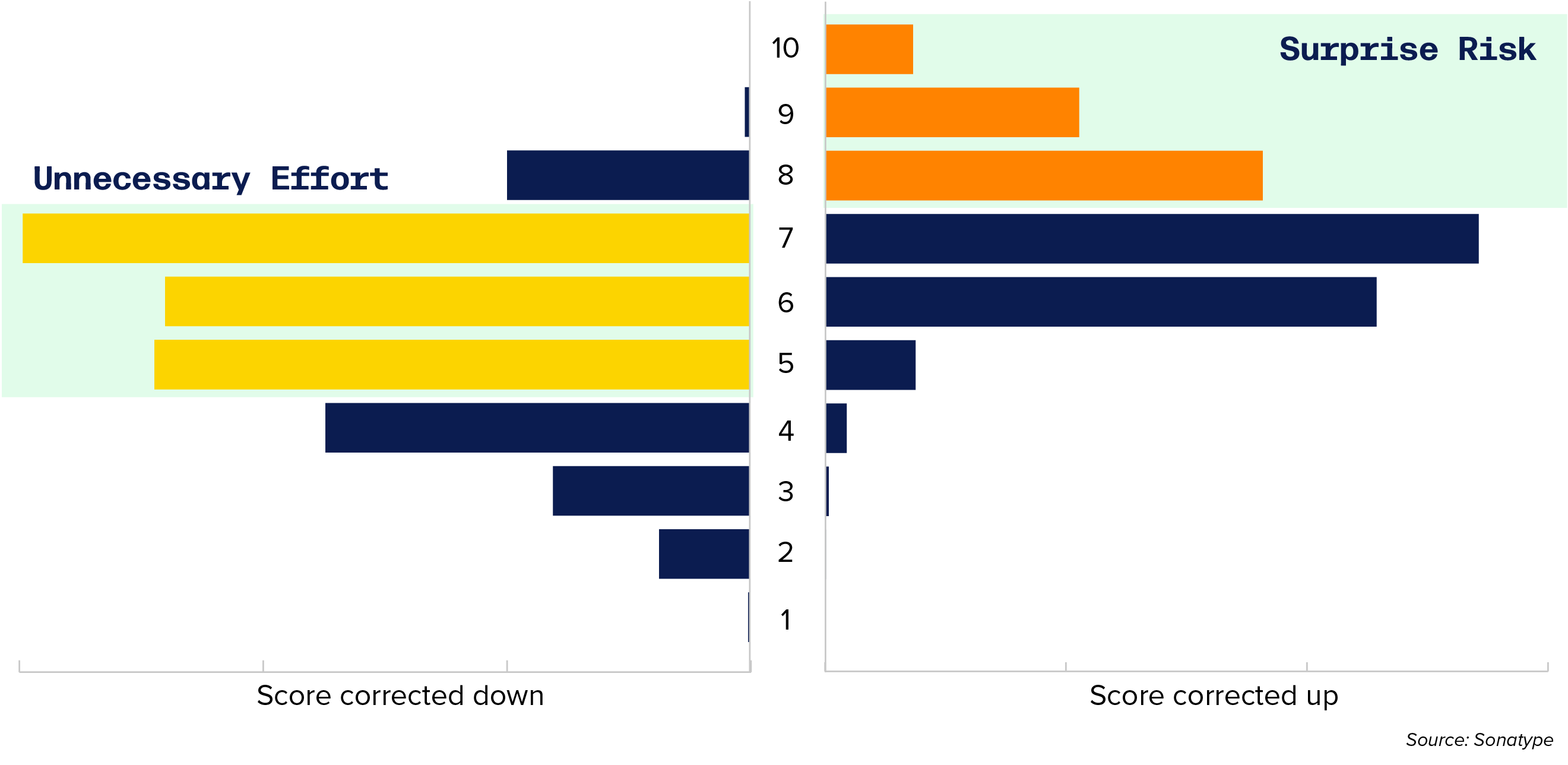
This bar chart depicts public vulnerability score corrections by score severity, 10 through 1
Figure 4.4 Average Number of Components (Packages) Per Application, by Ecosystem
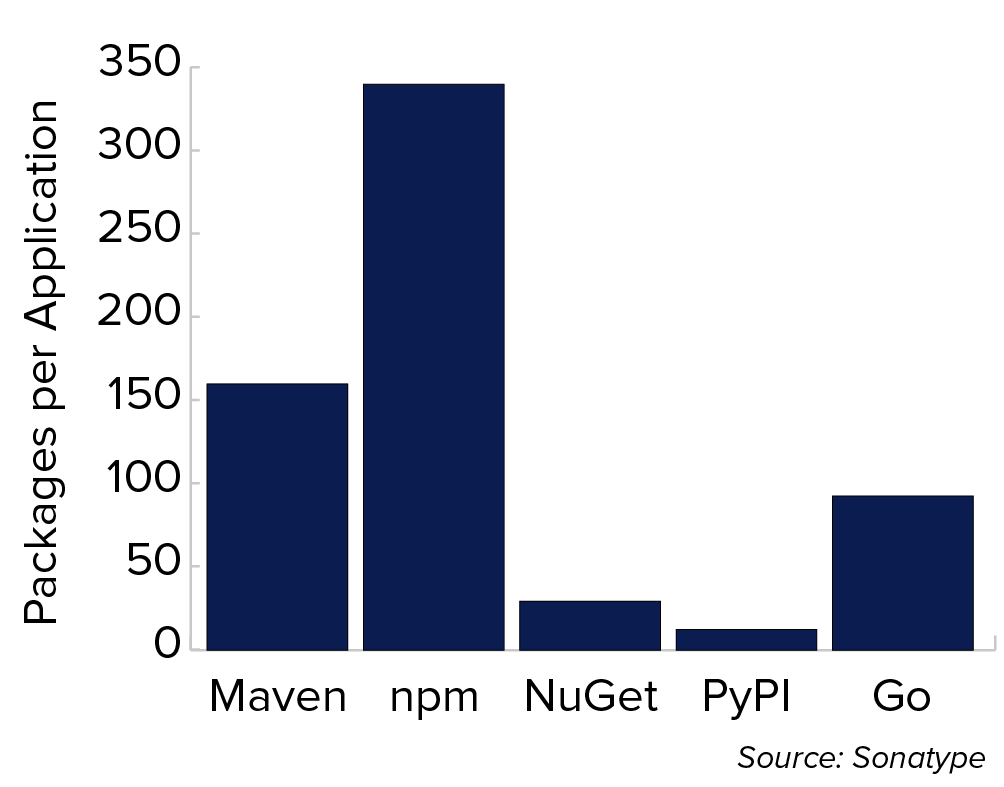
This bar chart shows the average number of ecosystem packages used by an application, covering Maven, npm, NuGet, PyPI, and Go.
Figure 4.5 Average Number of Vulnerabilities in Top 10 Most Popular Packages, by Ecosystem
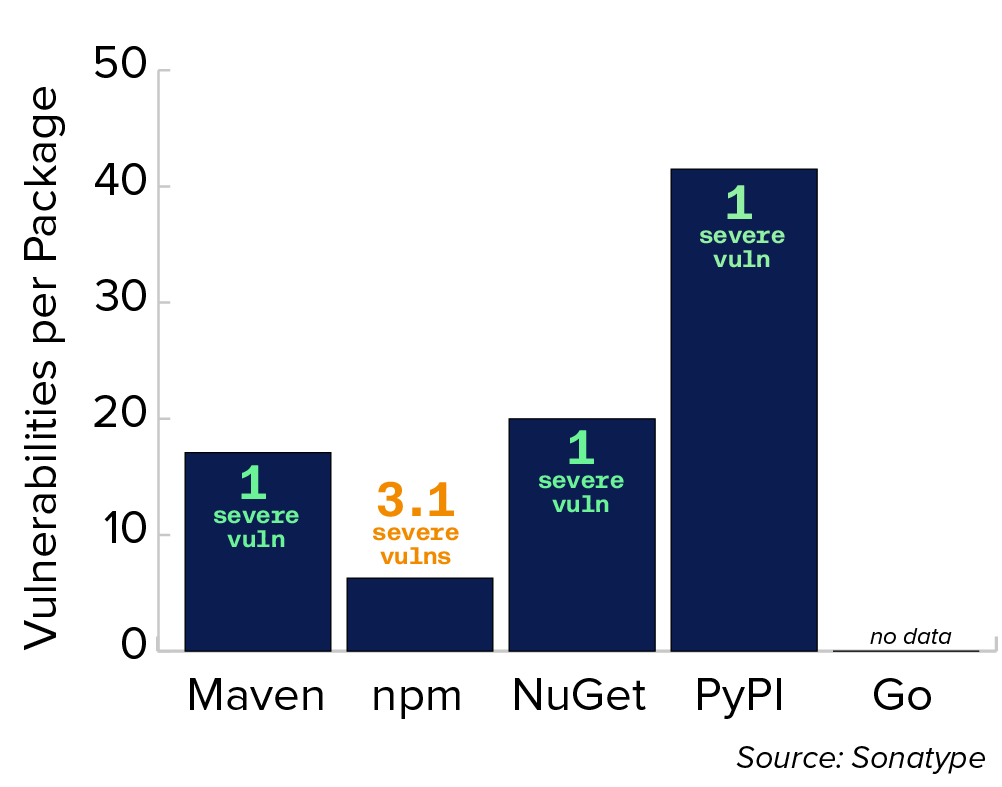
This bar chart shows the average vulnerability counts for the top 10 most popular packages by ecosystem (Maven, npm, NuGet, PyPI, and Go), along with the number of severe vulnerabilities.
Figure 4.7 Unique License Sets per Project
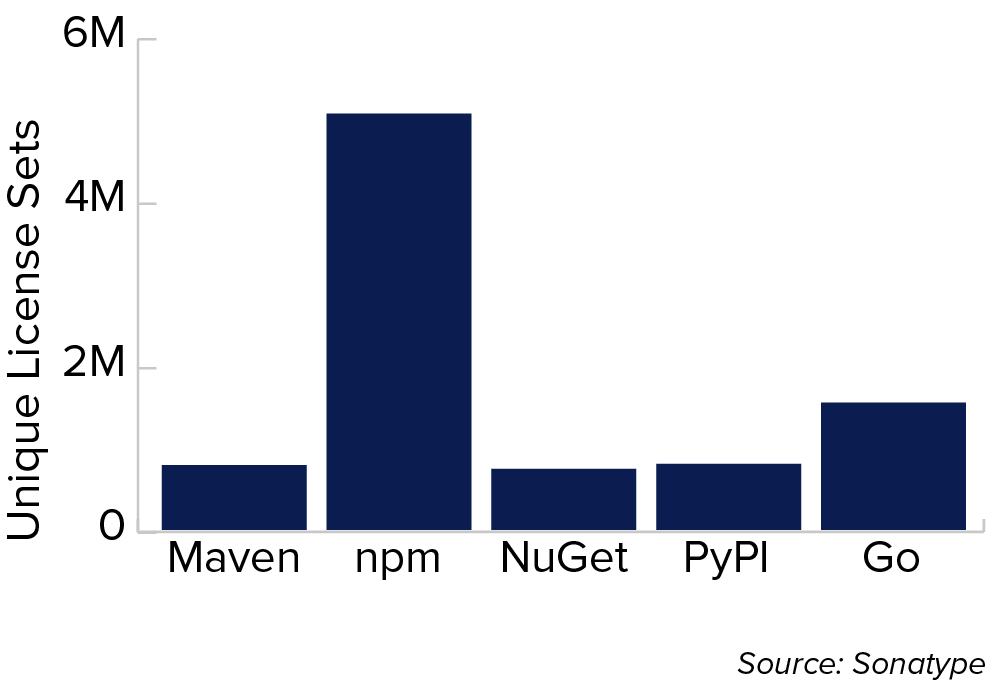
This bar chart shows the sum of the unique licenses sets per project (not including the first license set) by ecosystem: Maven, npm, NuGet, PyPI, Go).
Figure 4.8 Open Source Compliance Legal Review Time
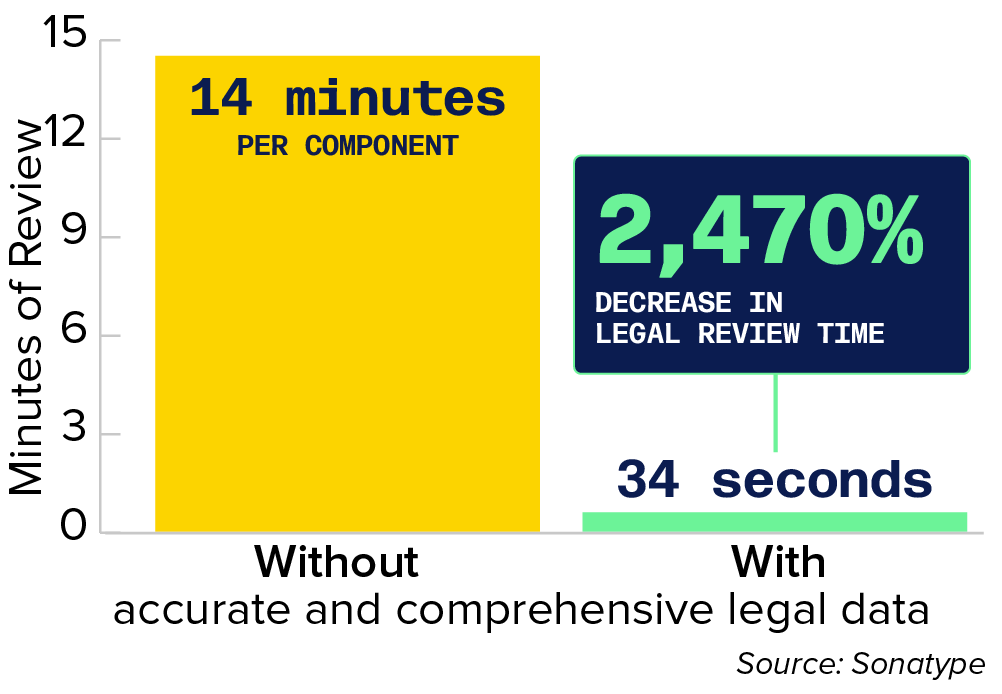
This bar chart illustrates efficiency gains in legal review time by comparing duration without and with accurate and comprehensive legal data.

