Software Supply Chain Management
Part 2: The Dawn of Component Software Development
Open source was a wildcard and the subject of much debate in the 2000s, but there’s little question now about its viability or usefulness. Instead, it’s come to define the whole industry and shows no signs of slowing down.
Component software is still growing rapidly with more than 2.2 trillion downloads across the top 4 open source programming languages in 2021. There were 497 billion downloads recorded for Java alone in Maven Central.

Open source Java component download totals by year.
The reality is that software is not just written but put together from parts. Even Linux, one of the most successful results of open source methodology, was itself built from component software projects from the start. Modern Linux is both a recipient of the software supply chain and a component for other projects.
These days, software is rarely built from scratch. And why wouldn’t developers draw upon the freely available, high-quality software to resolve their development tasks? It's like if 1,000 people work on your team rather than 10. Development teams rely on third-party and open source components to ship code and innovate faster without reinventing the wheel.
These components are called “dependencies,” and each dependency introduces potential risk in the form of security vulnerabilities, license problems, or quality issues. Many dependencies rely on other open source components, also known as “transitive dependencies,” making it harder to identify the original sources of risk.
Types of Software Dependencies
When you talk about the software supply chain, it’s important to talk about both components and subcomponents. This is analogous to how a car engine is made up of thousands of parts and each one of those are sourced from their own software supply chain.
- Direct Dependencies - Open source components are often added directly to the codebase (or their dependency tree) by software engineers. Further, a direct dependency is referenced directly by the program itself and are the “parents.” They control who their children (transitive dependencies) are, and whether or not they have any at all.

- Transitive Dependencies - These occur when a declared dependency requires additional open source components to run properly. These are often problematic because vulnerabilities or quality issues are often not declared or explored at this level. Because they’re less accessible to developers, this makes issues difficult to remediate.

By using these third-party components in their applications, organizations are assuming responsibility for code that their teams did not write. Similarly, understanding transitive dependencies as part of your InnerSource code (or the code you package yourself like open source) is crucial. The risk to an application from open source software and InnerSource can be managed and prevented through Software Composition Analysis (SCA).
We’ll dive even deeper into this when we talk about dependency management and SCA more in-depth in Part 4: The Basics of Software Supply Chain Management.
Artifact Management and Repositories
Understanding the software supply chain comes from the process by which software components are gathered, managed, and distributed. As we talk about componentized software — we wanted to go a little deeper. Software is more than just source code, it’s a collection of elements known as artifacts.
What is an Artifact?
The word “artifact” likely calls to mind something ancient and stored in a museum, but they can also refer more broadly to creations of a person or group. For software developers, artifacts capture and identify the various parts of creating software, including source code, use cases, models, requirements, design documents, and more.
[Artifacts] help other developers see the thought process behind what goes into developing a piece of software. This, in turn, helps lead developers to further decisions and gives them a better understanding of how to proceed.
Repository Managers
Repository managers are servers that store and retrieve artifacts. When you write a piece of software, you are often depending on external libraries. If you are developing a system to send a rocket into space, you might depend on an artifact that provides functions to calculate the effects of gravity. If you are building a website, you'll likely use a framework designed to serve text and images to visitors.
Public (Upstream) Repositories
Repositories like Maven Central and npm serve as upstream global libraries that store all open source components. These publicly visible servers have tens of millions of users throughout the world, fed by hundreds of thousands of open source projects. It’s akin to a modern-day "Library of Alexandria,” serving as a center for knowledge and learning, but for open source components.
Services like these greatly reduce the work required to distribute artifacts to millions of developers. Before the advent of public repositories, users would have to manually update dependencies, and open source projects would have to try to get the word out so people knew about a software release. Today, releasing new open source components to the world is a non-event.
Binary Repository Managers (Caching service)
Unlike the other repository managers, binary repository managers are established by individual groups or teams for their own use. They serve a few important functions as part of a modern software development lifecycle.
Keep a copy on file
These managers work as “proxies” or backups, to repositories such as Maven Central, npm, and other repository managers. When a new component is needed, managers fetch it from the repository and cache a copy locally for later use. This is important because even brief outages of repositories can cause developers significant grief. Developers save both bandwidth and retrieval time in connecting to artifact management storage.
Additionally, components will sometimes disappear from hosted repos. This poses a significant threat to all your apps, especially legacy apps that are still receiving support. Having a local copy of the repository reduces risk. And since the copy is local, you can manage it directly, customizing it to suit your organization’s needs.
This is especially crucial for enterprise development teams, which are often large and widely distributed. An efficient infrastructure and a shared set of assumptions about how software is developed can enable collaboration and speed.
Repository managers can also work as a host for internal artifacts, such as a custom database input or a compliance check specific to your company. It functions as a “single source of truth” for the binaries used in your build processes. An example is Sonatype’s Nexus Repository.
Just as public repositories brought efficiency to an entire world of software developers, running an internal, binary repository manager brings efficient collaboration between developers and teams. If one team develops a library used by another team, they can use an internal repository manager to distribute software releases internally as part of their InnerSource tools. If your development teams are delivering applications to an operations group for deployment, they can use a repository manager as a way to share final products.
Containers
Third-party open source applies to almost all software in development today from embedded tools, desktop, cloud, virtual machines, and more. However, one of the most visible results of the software supply chain is in Containerization. Here, the speed of development and deployment aided by a consistent environment in many ways puts Container software out front.
Press around the topic persistently accompanied with container ship photos is no accident:
“Container technology gets its name from the shipping industry. Rather than come up with a unique way to ship each product, goods get placed into steel shipping containers, which are already designed to be picked up by the crane on the dock, and fit into the ship designed to accommodate the container’s standard size. In short, by standardizing the process, and keeping the items together, the container can be moved as a unit, and it costs less to do it this way. (TechRadar)”
Benefits and Adoption
Containers allow apps to be easily shared and deployed with:
- Consistent environment and tools
- Predictable building tools
- Faster deployment
Containers can act as a common language between development and IT operations. And when configured properly, the operations team can utilize containers to assemble environments without compromising security.
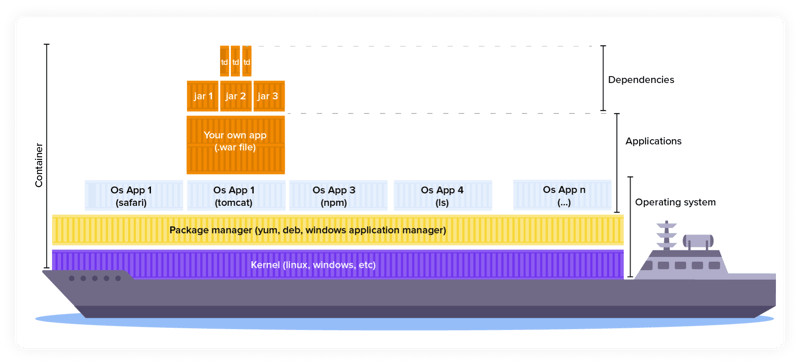
Image adapted from Docker.
These features mean that container service for deploying software has exploded since 2013. As reported in our 2020 State of the Software Supply Chain Report
“Pulls of container images topped 8 billion for the month of January. This means annualized image pulls from the repository should top 96 billion this year. To keep pace with demand, suppliers pushed 2.2 million new images to DockerHub over the past year – up 55% since our last report.”
It shows no signs of slowing down, with Gartner projections that 75% of organizations globally will run applications from containers in 2022, up from 30% in 2020.
Because containers also rely upon the same software dependencies that power other software but with a more rapid turnaround makes them immediate targets of attack. As a result, attacks on containers may be indicative of broader attacks on the software supply chain. And effective security means patrolling for component vulnerabilities, as well as compliance issues and misconfigurations.
The solution to this problem, and the cornerstone of good security hygiene, is the ability to detect and mitigate vulnerabilities in all phases of the SDLC. This includes build, registry, and production environments.
Component Licensing
Put very simply, a software license is a binding agreement between the software’s author and the user that explains how the software may be used. Typically, the license permits the user to read, modify, and use the component as long as they follow some rules.
When software is described as “open source,” it means that the source code is made available for others to see and read. An open source license is just a license that declares the software is open source - but as we mentioned above, that doesn’t usually mean it is just “free to use” whenever and wherever.
In the early stages of open source software components, following the terms of a license were easy because there were only a few and they were usually of a small group. However, as componentized software has grown, licensing has become a complex issue. Within just Maven Central, 95% of the components are split across 17 different licenses, and the remaining 5% of components are split across a whopping 307 other licenses.

Component License Compliance
The focus of license compliance is on leveraging policy management to ensure developers are choosing components that mitigate legal risk. However, many open source components come with additional requirements. This may include legal obligations. Sometimes this is as simple as mentioning the author and in other cases it may involve sharing the modified source code to the community.
Even just the most common obligations can be taxing. “Attribution” licenses, meaning that you include an OSS component’s license text, notice text, copyright holders, contributors, and/or source code are non-simple for hundreds of dependencies. In fact, typical applications contain upwards of 128 dependencies, and gathering all the required data can sap up to 58 hours of productivity. (more)
Again, automation is key here to avoid burdening skilled developers with license gathering and update tasks.